-
Ignasi Clavera
PhD Student. UC Berkeley.
I am a third year PhD student in CS at UC Berkeley advised by Pieter Abbeel in the Berkeley Artificial Intelligence Research (BAIR) Lab.
My research is at the intersection of machine learning and control. Specifically, I aim to enable robotic systems to learn how to perform complex tasks efficiently.
iclavera [at] berkeley [dot] eduRecent Preprints
-
-
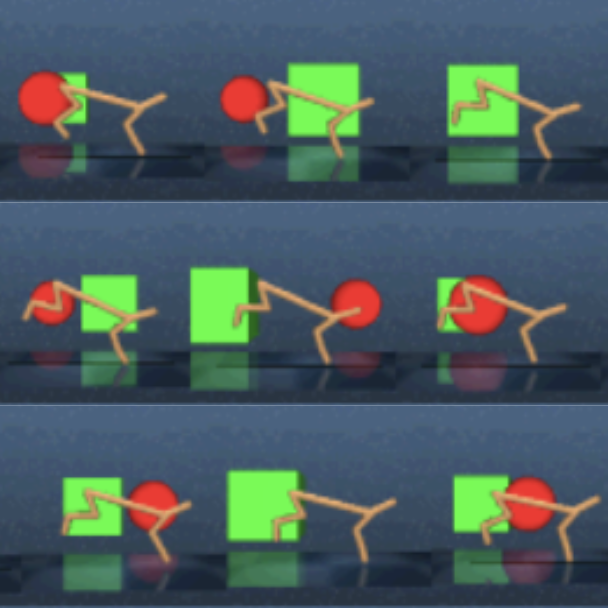
Mutual Information Maximization for Robust Plannable Representations
Extending the capabilities of robotics to real-world complex, unstructured environments requires the capability of developing better perception systems while maintaining low sample complexity. When dealing with high-dimensional state spaces, current methods are either model-free, or model-based with reconstruction based objectives. The sample inefficiency of the former constitutes a major barrier for applying them to the real-world. While the latter present low sample complexity, they learn latent spaces that need to reconstruct every single detail of the scene. Real-world environments are unstructured and cluttered with objects. Capturing all the variability on the latent representation harms its applicability to downstream tasks. In this work, we present mutual information maximization for robust plannable representations (MIRO), an information theoretic representational learning objective for model-based reinforcement learning. Our objective optimizes for a latent space that maximizes the mutual information with future observations and emphasizes the relevant aspects of the dynamics, which allows to capture all the information needed for planning. We show that our approach learns a latent representation that in cluttered scenes focuses on the task relevant features, ignoring the irrelevant aspects. At the same time, state-of-the-art methods with reconstruction objectives are unable to learn in such environments.
-
-
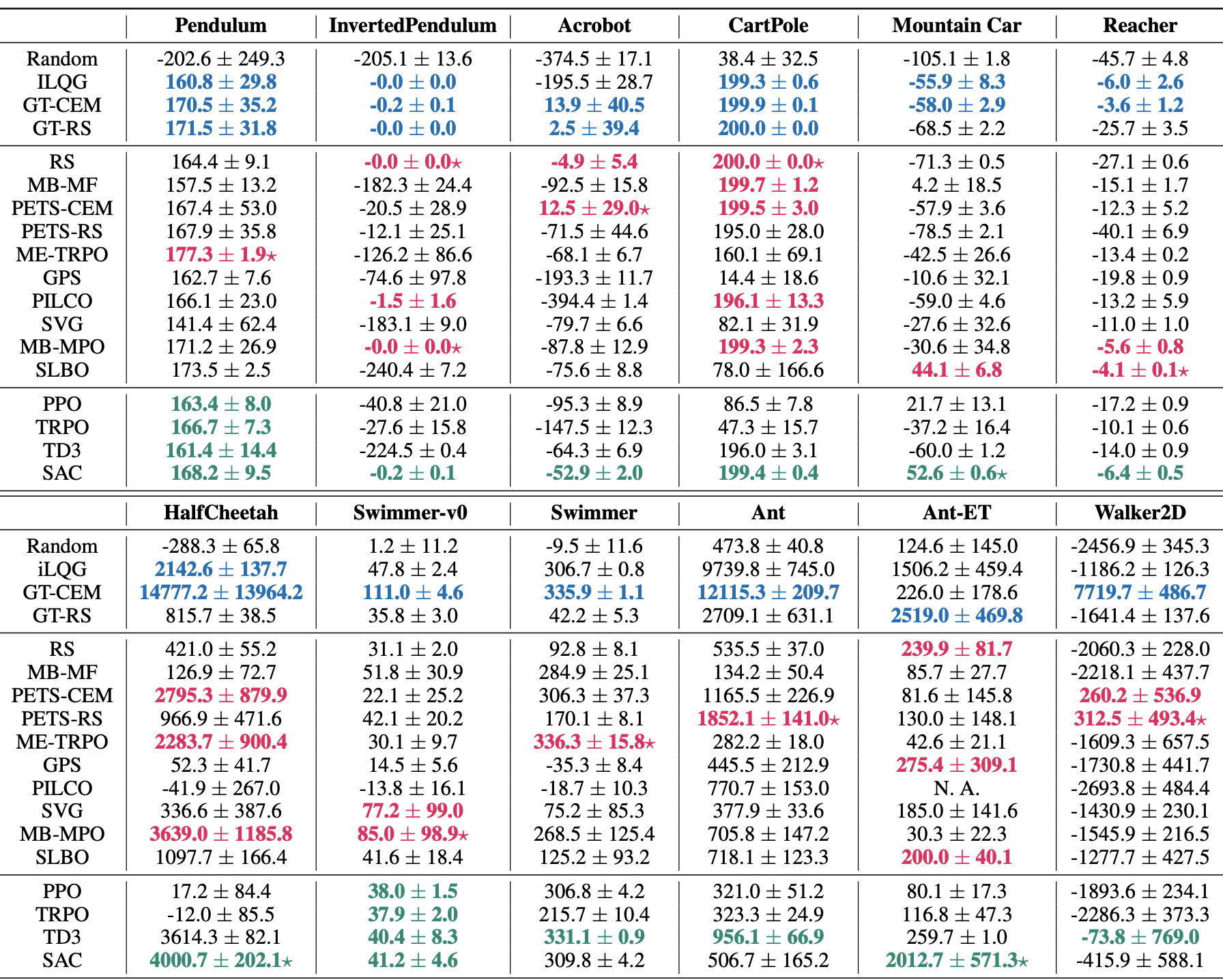
Benchmarking Model-Based Reinforcement Learning
Model-based reinforcement learning (MBRL) is widely seen as having the potential to be significantly more sample efficient than model-free RL. However, research in model-based RL has not been very standardized. It is fairly common for authors to experiment with self-designed environments, and there are several separate lines of research, which are sometimes closed-sourced or not reproducible. Accordingly, it is an open question how these various existing MBRL algorithms perform relative to each other. To facilitate research in MBRL, in this paper we gather a wide collection of MBRL algorithms and propose over 18 benchmarking environments specially designed for MBRL. We benchmark these algorithms with unified problem settings, including noisy environments. Beyond cataloguing performance, we explore and unify the underlying algorithmic differences across MBRL algorithms. We characterize three key research challenges for future MBRL research: the dynamics bottleneck, the planning horizon dilemma, and the early-termination dilemma.
All Papers
-
-
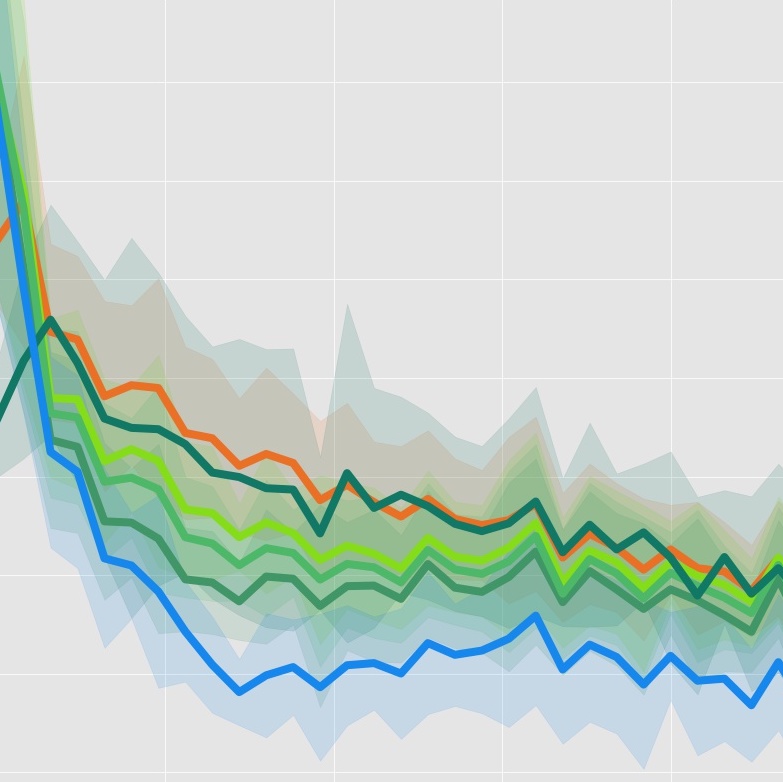
Model-Augmented Actor-Critic: Backpropagating through Paths
International Conference on Learning Representations (ICLR), 2020
Current model-based reinforcement learning approaches use the model simply as a learned black-box simulator to augment the data for policy optimization or value function learning. In this paper, we show how to make more effective use of the model by exploiting its differentiability. We construct a policy optimization algorithm that uses the pathwise derivative of the learned model and policy across future timesteps. Instabilities of learning across many timesteps are prevented by using a terminal value function, learning the policy in an actor-critic fashion. Furthermore, we present a derivation on the monotonic improvement of our objective in terms of the gradient error in the model and value function. We show that our approach (i) is consistently more sample efficient than existing state-of-the-art model-based algorithms, (ii) matches the asymptotic performance of model-free algorithms, and (iii) scales to long horizons, a regime where typically past model-based approaches have struggled.
-

-
Sub-policy Adaptation for Hierarchical Reinforcement Learning
International Conference on Learning Representations (ICLR), 2020
Hierarchical reinforcement learning is a promising approach to tackle long-horizon decision-making problems with sparse rewards. Unfortunately, most methods still decouple the lower-level skill acquisition process and the training of a higher level that controls the skills in a new task. Leaving the skills fixed can lead to significant sub-optimality in the transfer setting. In this work, we propose a novel algorithm to discover a set of skills, and continuously adapt them along with the higher level even when training on a new task. Our main contributions are two-fold. First, we derive a new hierarchical policy gradient with an unbiased latent-dependent baseline, and we introduce Hierarchical Proximal Policy Optimization (HiPPO), an on-policy method to efficiently train all levels of the hierarchy jointly. Second, we propose a method of training time-abstractions that improves the robustness of the obtained skills to environment changes.
-

-
Asynchronous Methods for Model-Based Reinforcement Learning
Conference on Robot Learning (CORL), 2019
Significant progress has been made in the area of model-based reinforcement learning. State-of-the-art algorithms are now able to match the asymptotic performance of model-free methods while being significantly more data efficient. However, this success has come at a price: state-of-the-art model-based methods require significant computation interleaved with data collection, resulting in run times that take days, even if the amount of agent interaction might be just hours or even minutes. When considering the goal of learning in real-time on real robots, this means these state-of-the-art model-based algorithms still remain impractical. In this work, we propose an asynchronous framework for model-based reinforcement learning methods that brings down the run time of these algorithms to be just the data collection time. We evaluate our asynchronous framework on a range of standard MuJoCo benchmarks. We also evaluate our asynchronous framework on three real-world robotic manipulation tasks. We show how asynchronous learning not only speeds up learning w.r.t wall-clock time through parallelization, but also further reduces the sample complexity of model-based approaches by means of improving the exploration and by means of effectively avoiding the policy overfitting to the deficiencies of learned dynamics models.
-
-
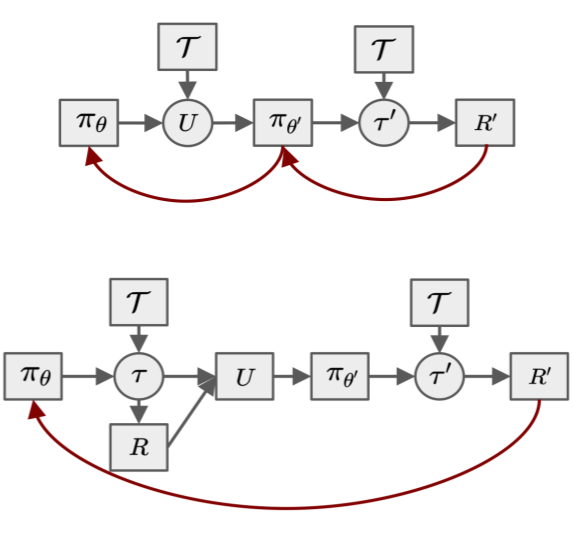
ProMP. Proximal Meta-Policy Search
International Conference on Learning Representations (ICLR), 2019
Credit assignment in Meta-reinforcement learning (Meta-RL) is still poorly understood. Existing methods either neglect credit assignment to pre-adaptation behavior or implement it naively. This leads to poor sample-efficiency during meta-training as well as ineffective task identification strategies. This paper provides a theoretical analysis of credit assignment in gradient-based Meta-RL. Building on the gained insights we develop a novel meta-learning algorithm that overcomes both the issue of poor credit assignment and previous difficulties in estimating meta-policy gradients. By controlling the statistical distance of both pre-adaptation and adapted policies during meta-policy search, the proposed algorithm endows efficient and stable meta-learning. Our approach leads to superior pre-adaptation policy behavior and consistently outperforms previous Meta-RL algorithms in sample-efficiency, wall-clock time, and asymptotic performance.
-

-
Learning to Adapt in Dynamic, Real-World Environments Through Meta-Reinforcement Learning
International Conference on Learning Representations (ICLR), 2019
Although reinforcement learning methods can achieve impressive results in simulation, the real world presents two major challenges 1) generating samples is exceedingly expensive, and 2) unexpected perturbations or unseen situations cause proficient but specialized policies to fail at test time. Given that it is impractical to train separate policies to accommodate all situations the agent may see in the real world, this work proposes to learn how to quickly and effectively adapt online to new tasks. To enable sample-efficient learning, we consider learning online adaptation in the context of model-based reinforcement learning. Our approach uses meta-learning to train a dynamics model prior such that, when combined with recent data, this prior can be rapidly adapted to the local context. Our experiments demonstrate online adaptation for continuous control tasks on both simulated and real-world agents. We first show simulated agents adapting their behavior online to novel terrains, crippled body parts, and highly-dynamic environments. We also illustrate the importance of incorporating online adaptation into autonomous agents that operate in the real world by applying our method to a real dynamic legged millirobot. We demonstrate the agent's learned ability to quickly adapt online to a missing leg, adjust to novel terrains and slopes, account for miscalibration or errors in pose estimation, and compensate for pulling payloads.
-
-
Model-Based Reinforcement Learning via Meta-Policy Optimization
Conference on Robot Learning (CORL), 2018
Model-based reinforcement learning approaches carry the promise of being data efficient. However, due to challenges in learning dynamics models that sufficiently match the real-world dynamics, they struggle to achieve the same asymptotic performance as model-free methods. We propose Model-Based Meta-Policy-Optimization (MB-MPO), an approach that foregoes the strong reliance on accurate learned dynamics models. Using an ensemble of learned dynamic models, MB-MPO meta-learns a policy that can quickly adapt to any model in the ensemble with one policy gradient step. This steers the meta-policy towards internalizing consistent dynamics predictions among the ensemble while shifting the burden of behaving optimally w.r.t. the model discrepancies towards the adaptation step. Our experiments show that MB-MPO is more robust to model imperfections than previous model-based approaches. Finally, we demonstrate that our approach is able to match the asymptotic performance of model-free methods while requiring significantly less experience.
-
-
Model-Ensemble Trust-Region Policy Optimization
International Conference on Learning Representations (ICLR), 2018
Model-free reinforcement learning (RL) methods are succeeding in a growing number of tasks, aided by recent advances in deep learning. However, they tend to suffer from high sample complexity, which hinders their use in real-world domains. Alternatively, model-based reinforcement learning promises to reduce sample complexity, but tends to require careful tuning and to date have succeeded mainly in restrictive domains where simple models are sufficient for learning. In this paper, we analyze the behavior of vanilla model-based reinforcement learning methods when deep neural networks are used to learn both the model and the policy, and show that the learned policy tends to exploit regions where insufficient data is available for the model to be learned, causing instability in training. To overcome this issue, we propose to use an ensemble of models to maintain the model uncertainty and regularize the learning process. We further show that the use of likelihood ratio derivatives yields much more stable learning than backpropagation through time. Altogether, our approach Model-Ensemble Trust-Region Policy Optimization (ME-TRPO) significantly reduces the sample complexity compared to model-free deep RL methods on challenging continuous control benchmark tasks.
-

-
Policy Transfer via Modularity and Reward Guiding
International Conference on Intelligent Robots and Systems (IROS), 2017
Non-prehensile manipulation, such as pushing, is an important function for robots to move objects and is sometimes preferred as an alternative to grasping. However, due to unknown frictional forces, pushing has been proven a difficult task for robots. We explore the use of reinforcement learning to train a robot to robustly push an object. In order to deal with the sample complexity of training such a method, we train the pushing policy in simulation and then transfer this policy to the real world. In order to ease the transfer from simulation, we propose to use modularity to separate the learned policy from the raw inputs and outputs; rather than training “end-to-end,” we decompose our system into modules and train only a subset of these modules in simulation. We further demonstrate that we can incorporate prior knowledge about the task into the state space and the reward function to speed up convergence. Finally, we introduce ”reward guiding” to modify the reward function and further reduce the training time. We demonstrate, in both simulation and real-world experiments, that such an approach can be used to reliably push an object from many initial positions and orientations.
-
